DATA-146
This project is maintained by pterwoo
Midterm Corrections
The first step to answering the questions is importing the necessary libraries and data, and defining the DoKFold function.
Importing Libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split as tts
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import Ridge
from sklearn.linear_model import Lasso
Importing the california_housing dataset
data = fetch_california_housing(as_frame= True)
housing = data.frame
X = data.data
y = data.target
Defining the DoKFold function
def DoKFold (model, X, y, k, standardize = False, random_state = 146):
import numpy as np
from sklearn.model_selection import KFold
kf = KFold(n_splits = k, shuffle = True, random_state=random_state)
if standardize:
from sklearn.preprocessing import StandardScaler as SS
ss = SS()
train_scores = []
test_scores = []
train_mse = []
test_mse = []
for idxTrain, idxTest in kf.split(X):
Xtrain = X[idxTrain, :]
Xtest = X[idxTest, :]
ytrain = y[idxTrain]
ytest = y[idxTest]
if standardize:
Xtrain = ss.fit_transform(Xtrain)
Xtest = ss.transform(Xtest)
model.fit(Xtrain,ytrain)
train_scores.append(model.score(Xtrain, ytrain))
test_scores.append(model.score(Xtest, ytest))
ytrain_pred = model.predict(Xtrain)
ytest_pred = model.predict(Xtest)
train_mse.append(np.mean((ytrain - ytrain_pred) ** 2))
test_mse.append(np.mean((ytest - ytest_pred) ** 2))
return train_scores, test_scores, train_mse, test_mse
Question 15
Finding the variable that is the most correlated with the target variable is as simple as running the following:
housing.corr()
This returns a matrix with the correlations of the variable with other variables.
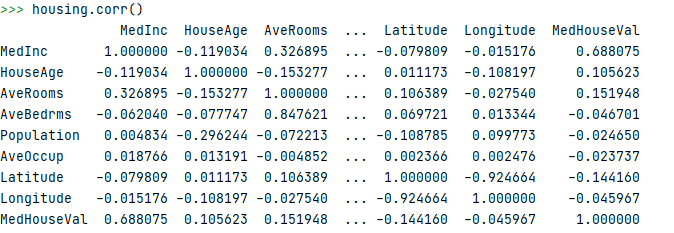
From this matrix we can see that the MedInc is most correlated with our target variable, MedHouseVal.
I got this question correct.
Question 16
To transform the data, we use the StandardScaler.fit_transform() function.
ss = StandardScaler()
st_X = ss.fit_transform(X)
Then, create a dataframe with the standardized X values and the target y values.
st_X_df = pd.DataFrame(st_X, columns= data.feature_names)
st_Xy_df = st_X_df.copy()
st_Xy_df['y'] = y
Finally, use the same function from question 15 to study the correlations.
st_Xy_df.corr()
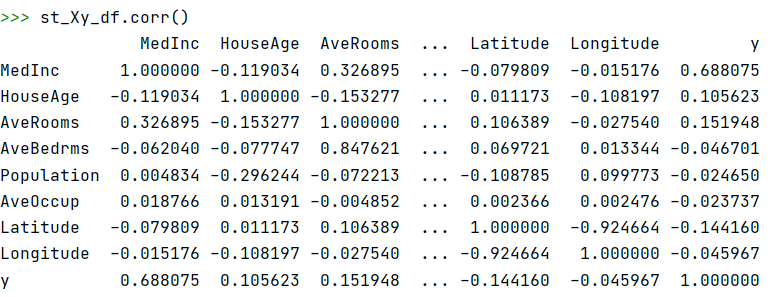
we see that the correlations with the target y values are equivalent to those from question 15.
I got this question correct.
Question 17
Perform a linear regression with just the MedInc variable and the y value.
lin_reg = LinearRegression()
X_df = pd.DataFrame(data.data)
lin_reg.fit(X_df['MedInc'].values.reshape(-1,1),y)
np.round(lin_reg.score(X_df['MedInc'].values.reshape(-1,1),y),2)
This returns a coefficient of determination of 0.47
I got this question correct.
Question 18
The questions requires performing a linear regression on the standardized dataset.
To do this, we can use the previously defined DoKFold function.
k = 20
train_scores, test_scores, train_mse, test_mse = DoKFold(lin_reg, X,y,k,True)
Print the mean values of the training/testing scores
print(np.mean(train_scores), np.mean(test_scores))
This should return:
0.6063019182717753 0.6019800920504694
I got this question wrong initially because I misinterpreted the question. I subsetted the dataset to perform linear regression on only the MedInc varaible and the target, not the entire dataset.
Question 19
Perform ridge regression with the same dataset.
k = 20
rid_a_range = np.linspace(20, 30, 101)
rid_tr = []
rid_te = []
rid_tr_mse = []
rid_te_mse = []
for a in rid_a_range:
mdl = Ridge(alpha=a)
train, test, train_mse, test_mse = DoKFold(mdl, X, y, k, True, random_state=146)
rid_tr.append(np.mean(train))
rid_te.append(np.mean(test))
rid_tr_mse.append(np.mean(train_mse))
rid_te_mse.append(np.mean(test_mse))
idx = np.argmax(rid_te)
print('Optimal alpha value: ' + format(rid_a_range[idx], '.3f'))
print('Training score for this value: ' + format(rid_tr[idx], '.5f'))
print('Testing score for this value: ' + format(rid_te[idx], '.5f'))
This should return:
Optimal alpha value: 25.800
Training score: 0.60627
Testing score: 0.60201
I had the same issue here with the previous question. I used a single feature variable instead of the entire dataset.
Question 20
Perform lasso regression.
las_a_range = np.linspace(0.001, 0.003, 101)
las_tr = []
las_te = []
las_tr_mse = []
las_te_mse = []
for a in las_a_range:
model = Lasso(alpha=a)
train, test, train_mse, test_mse = DoKFold(model, X, y, 20, True, 146)
las_tr.append(np.mean(train))
las_te.append(np.mean(test))
las_tr_mse.append(np.mean(train_mse))
las_te_mse.append(np.mean(train_mse))
idx = np.argmax(las_te)
print('Optimal alpha value: ' + format(las_a_range[idx], '.5f'))
print('Training score for this value: ' + format(las_tr[idx], '.5f'))
print('Testing score for this value: ' + format(las_te[idx], '.5f'))
This returns:
Optimal alpha value: 0.00186
Training score for this value: 0.60616
Testing score for this value: 0.60213
Again, I made the mistake of using one feature variable instead of the entire dataset.
Question 21
To find out which regression model has the smallest correlation for the least correlated variable, we must first figure out which variable is the least correlated with the target value. We can refer back to the table generated from question 16. The variable least correlated with the target is AveOccup
lin = LR; rid = Ridge(alpha=25.8); las = Lasso(alpha=0.00186)
lin.fit(st_X, y); rid.fit(st_X,y);las.fit(st_X,y); # st_X is the array of standardized X values on
lin.coef_[5],rid.coef_[5],las.coef_[5]
This returns
(-0.039326266978148866, -0.039412573728940366, -0.03761823364553458)
The model that returned the lowest correlation was Lasso regression.
I got this question correct.
Question 22
The process of this question is largely the same as the previous question. We refer back to the table from question 17. The variable most correlted with the target is MedInc
Since we already fit the data in the previous question, we just need to execute:
lin.coef_[0],rid.coef_[0],las.coef_[0]
which returns
(0.82961930428045, 0.8288892465528181, 0.8200140807502059)
Question 23
To do this, we simply use the minimum MSE value instead of the maximum R2 value.
idx = np.argmin(rid_te_mse)
print('Optimal alpha value: ' + format(rid_a_range[idx], '.3f'))
print('Training score for this value: ' + format(rid_tr_mse[idx], '.5f'))
print('Testing score for this value: ' + format(rid_te_mse[idx], '.5f'))
This returns
Optimal alpha value: 26.100
Training score for this value: 0.52427
Testing score for this value: 0.52876
This question and the next question gave me the most issues. I was able to calculate MSE in a for loop, but the method that I used was incorrect. The correction I made here calculates MSE inside the DoKFold function and makes it convenient to do the operation above.
Question 24
We execute the same code from question 23, just with different variables.
idx = np.argmin(las_te_mse)
print('Optimal alpha value: ' + format(las_a_range[idx], '.3f'))
print('Training score for this value: ' + format(las_tr_mse[idx], '.5f'))
print('Testing score for this value: ' + format(las_te_mse[idx], '.5f'))
This returns
Optimal alpha value: 0.00186
Training score for this value: 0.60616
Testing score for this value: 0.60213
I had the same problem here as the previous question.